¶Scheduling bottlenecks in 3D filter acceleration
As I noted last time, there are reasons why VirtualDub's 3D filter acceleration has problems if a display mode switch is triggered. There are, however, also some performance bottlenecks in the implementation in 1.9.5 that I'm working on resolving. Here's an example:

This is a screenshot from VirtualDub's real-time profiler, showing CPU usage during a video analysis pass using a mix of CPU and GPU filters (warp sharp on GPU + rotate2 on CPU). The main things to notice are the long V-Filter section on the Processor and the idle times on the Filter 3D Accel thread. This is the time during which the video filter system runs. The basic problem here is that the video filter system is single-threaded and all calls into the accelerator are done as blocking calls, synchronizing the threads. The result is that the processing thread is blocked while the readback is occurring (the long operation with Poll and Readback blocks) and then the acceleration thread goes idle while the processing thread is busy doing other tasks. This limits concurrency between the CPU and the GPU.
In my current dev branch, the situation has changed a bit.
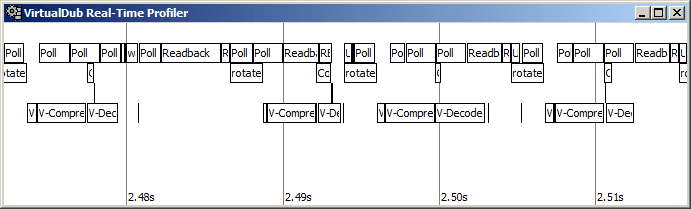
The first thing to notice... is the lack of color. That's because I'm currently redoing the profiling architecture to be lighter weight and to capture a performance log instead of just per-second snapshots. I didn't think it would make a lot of difference, but now it definitely seems harder to read without the color coding.
That aside, you can see the the accelerator thread (top thread) is much more busy in this version. There are two reasons for this. The first is that in this build the filter system has the ability to "hand off" a particular invocation of a filter instance. For various reasons the filter system cannot currently be run multithreaded, but the filter instances can -- so what the filter system does is set up a frame, hand it off for asynchronous execution, and then later closes the frame and collects the output once the filter is done. The second reason for the improvement is that the render pipeline can now queue more than one frame request in the filter system. It still isn't possible to allow a single filter instance to process multiple frames in parallel, since the filters have mutable state which generally prohibits this, but this does permit different filters to queue up behind each other, so that the accelerator can work on the warpsharp instance for one frame and then download another frame without intervention from the main processing thread. The result is a modest increase in frame rate for this chain, going from about 17 fps to 20 fps for about a 20% improvement.